编写好代码¶
在整个PLYMI的过程中我们学习的重点在于编写合法Python代码的规则。也就是说,我们保证了我们的计算机能够理解我们为其编写的指示。在这里,我们将讨论让人们轻松理解我们的代码的方法。具体来讲,我们会学习:
“PEP8”:Python代码的官方风格指南
Python为函数添加所谓“类型暗示”的系统
如NumPy和Napolean说明文档的正式说明文档细则
讨论这些项目的最直接的目的在于帮助我们编写易懂和易维持的代码。长期上来,它们将使得我们的项目长寿并对其他更多人有用。你可能会惊讶于一个代码库在设计事没有给予细节和说明文档足够多考量时可以多快地衰退,并变得难懂和难用,甚至对其创造者也是如此。
你很难夸大本话题的重要性。
Python代码的PEP8风格指南¶
PEP是什么?
我们将在本节引用多个“PEP”。PEP是Python Enhancement Protocol(Python增强协议)的缩写。任何对Python语言,CPython直译器,或Python标准库的模组的根本性改变必须首先作为一个PEP提交并经历一个审批过程。你可以在这里读取更多有关PEP的宗旨和准则。完整的PEP索引可以在这里 找到。
PEP8是一个为Python社区提供有条理的代码风格指南的设计文档。它提供了一大组的在你的代码中做有关风格选择时的“这么做”和“不这么做”的指示。比如说,PEP8呼吁用户在二元数学操作赋旁边添加一个空格;如下:
# 这么做:
x = x + 1
# 不这么做:
x=x+1
这份文档的最大影响在于它指导Python用户去编写看起来相似的代码。如此,编写符合PEP8的代码将会使得你的代码让其它人更容易阅读它,反之亦然。请注意,在PLYMI各处的代码块均符合此风格指南。
我们将会指出PEP8指南中和本文阅读中的那类代码最相关的一些细则。虽说如此,你应该花一些时间阅读完整的PEP8,并在编写代码时经常参阅它。这样做的话你不会需要太多时间就会自然而然记住大部分细则了。最后,请注意很多IDE有着叫做“linter”的工具来检查你的代码并在代码违反PEP8规则时提出警告。这是一个极佳的保证你代码符合风格指南的功能。
Python式编程¶
我们将会学习一些如何编写地道的Python代码的守则。也就是说,它们将直到我们去使用Python创造者希望我们使用的语法。
比如说,永远使用否定语 is not 和 not in。比如说,not x is None 本 x is not None 功能上完全相同,但是后者明显更加可取,因为它和英文语法相同。
# 这么做:
x not in collection
# 不这么做:
not x in collections
# 这么做:
x is not None
# 不这么做:
not x is None
不要使用括号来创建不必要的括号组。你应在提供函数签名,调用对象(如调用函数),结合数学表达式,定义生成器表达式,和组合多行表达式时使用括号。
# 这么做:
if x > 2:
x += 1
# 不这么做:
if (x > 2):
x += 1
# 这么做:
if (long_variable_name in a_long_list_name
and long_variable_name not in another_long_name):
x += 1
# 不这么做:
if long_variable_name in a_long_list_name and long_variable_name not in another_long_name:
x += 1
# 这么做:
for i in numbers:
x.append(i**2)
# 不这么做:
for i in numbers:(
x.append(i**2)
)
最后,在条件表达式中使用非布尔对象的布尔值。比如说,你可以使用空序列对象会在条件语句中计算为 False 的事实。
# 这么做:
if list_of_names:
x += 1
# 不这么做:
if len(list_of_names) > 0:
x += 1
# 这么做:
result = "on" if integer_flag else "off
# 不这么做:
result = "on" if integer_flag != 0 else "off
命名规则¶
类名字应该使用 CamelCase(驼峰式大小写格式,也叫做 CapWords)格式化规则,而函数和变量应该使用全小写的名字。在长的小写名字中你应该使用下划线使其更可读(如 snake_case)。
# 类的命名规则
# 这么做:
class ShoppingList:
pass
# 不这么做:
class shoppingList:
pass
# 本地变量和函数的命名规则
# 这么做:
list_of_students = ["Alyosha", "Biff", "Celine"]
def rotate_image(image):
pass
# 不这么做:
ListOfStudents = ["Shmangela", "Shmonathan"]
def rotateimage(image):
pass
请注意,为类名使用 CamelCasing 和为函数和变量名使用 snake_casing 并没有什么根本的正确性。虽然如此,大部分Python用户会期望代码符合这些规则,且会在你不这么做的时候难以阅读你的代码。
常量——其值在代码任何地方都不会改变的变量——应该使用全大写(ALL_CAPS)格式。你可以使用下划线来提升可读性。
# 常量的命名规则
# 这么做:
BOILING_POINT = 100 # 摄氏度
# 不这么做:
boiling_point = 100 # 摄氏度
你可以使用前置下划线来命名只会在开发者内部代码使用的变量。比如说,如果你看到了 _use_gpu = True 这行代码,这意味着变量 _use_gpu 应该仅仅被编写此(模组)代码的人浏览并使用。请注意,这个变量不会和 use_gpu 有着不同的行为——前置的下划线仅仅是一个视觉上的标记。
你可以在你的变量名会和Python保留的名字冲突时添加一个滞后的下划线。比如说,你不能将一个变量命名为 class,,因为它是Python为定义新类对象所保留的词。反而,你可以将其命名为 class_。你应该尽量避免使用这个技巧。
比起这些,最重要的点在于给你的变量描述性的名字。
# 这么做:
for temperature in list_of_temperatures:
pressure = gauge(temperature)
# 不这么做:
for thing in x:
thingthing = f(thing)
# 不,这并不是夸大其词。
# 我真的见过这样子的代码。
缩进和字距¶
在创建缩进时,你应该使用空格而不是tab键。
限定作用域的缩进应该永远使用四个空格。
# 使用四个空格来限定作用域
# 这么做:
if x > 0:
x = 2 # 由四个空格缩进
# 不这么做:
if x > 0:
x = 2 # 由不是四个空格缩进
在单(逻辑)行代码占用两或以上行的空间时,使用悬挂的缩进。你应该注意在括号或方括号中的内容竖向对齐:
# 使用悬挂缩进来处理长代码行
# 这么做:使用空格来对其函数签名中多行的
# 参数(译者注:中文没法对齐,抱歉啦!)
if isinstance(item, str):
output = some_long_function_name(arg1, arg2, arg3,
arg4, arg5, arg6)
# 不这么做:
if isinstance(item, str):
output = some_long_function_name(arg1, arg2, arg3,
arg4, arg5, arg6)
# 这么做:
grocery_list = {"apple": 2, "banana": 10, "chocolate": 1e34,
"toothpaste": 1, "shampoo": 1}
# 不这么做:第二行缩进不够
grocery_list = {"apple": 2, "banana": 10, "chocolate": 1e34,
"toothpaste": 1, "shampoo": 1}
# 这么做:
x = [[i**2 for i in list_of_ages if i > 10]
for list_of_ages in database]
# 不这么做:第二行缩进过头
x = [[i**2 for i in list_of_ages if i > 10]
for list_of_ages in database]
函数和类定义应由两个空行隔开:
# 使用两个空行隔开函数和类定义
# 这么做:
def func_a():
"""我是函数a"""
return 1
def func_b(): # 和 func_a 隔了两个空行
"""我是函数b"""
return 2
# 不这么做:
def func_c():
"""我是函数c"""
return 1
def func_d(): # 和 func_c 隔了一个空行
"""我是函数d"""
return 2
函数参数的默认值应不用空格写出。这也通用于在调用函数时使用参数名字的情况。
# 默认值不应该有空格
# 这么做:
def func(x, y=2):
return x + y
# 不这么做:
def func(x, y = 2):
return x + y
# 这么做:
grade = grade_lookup(name="Ryan")
# 不这么做:
grade = grade_lookup(name = "Ryan")
就像在正常英文中一样,逗号和冒号后应该在一个非空格的符号后,并之后跟着一个空格。这条规则的例外是在代码行尾的逗号/冒号或在切片中使用冒号。
# 逗号/冒号应后置一个空格
# 这么做:
x = (1, 2, 3)
# 不这么做:
x = (1,2,3)
x = (1 , 2 , 3)
# 这么做:
x = {1: "a", 2: "b", 3: "c"}
# 不这么做:
x = {1 : "a", 2 : "b", 3 : "c"}
x = {1:"a", 2:"b", 3:"c"}
# 这么做:
# (1,) 是一个包含整数1的元组。请回忆,(1) 等于
# 1。只有行尾的逗号才使得其被视作一个元组。
x = (1,)
# 不这么做:
x = (1, )
# 这么做:
# 简单的切片不应该有空格
sublist = x[1:4]
# 不这么做:
sublist = x[1: 4]
总而言之,使得你知道存在一个名为PEP8的Python风格指南是本小节最关键的目的。在读本小节之前,你可能都不会知道去搜索这么一个文档。当你有着关于代码风格的问题时会咨询PEP8才是这里本小节最重要的结果。
自动化风格:
虽然遵守一个清晰一致的风格为编写“好代码”是至关重要的,执行这些标准可能会很麻烦并耗力。这在你开始和其他人合作并编写大规模项目时会特别明显。幸运的是,有好几个很强大的工具存在来帮助我们自动化好的代码风格。
flake8:分析你的代码来执行PEP8标准并报告不好的代码,如未使用的变量。
像Visual Studio Code和PyCharm这样的IDE会自动对你的代码运行flake8或相似的linter。它们会在你的代码上添加可视的标记来高亮显示有问题的代码片段。你也可以从命令行运行这个工具,或设置使其和其它IDE和文本编辑器自动运行。
isort:“我来处理(I sort)你的Python导入,所以你不需要操心”
就像工具承诺的一样,它会自动为你管理在我们代码顶端快速变多的导入语句。它将按照字母顺序排序这些导入语句并根据PEP8将它们分组。
black:“你喜欢的任何代码风格,只要它是黑色的”
Black是一个决不妥协的代码格式器。如果你运行black,你不需要花时间来正确地格式化你的代码——它会每次用相同的方法格式化你的代码。虽然这会帮助你解决像分行,缩进,字距,和方括号这类事,但是编写Python式的代码和使用好的命名规则依然是你的责任。
知道这些工具存在是很有用的;当你成为一个越来越高效的Python程序员的同时,考虑将这些工具添加到你的工作流程中。
经验:
PEP8是面向Python社区的设计文本,其提供了一个有条理的编写Python代码的风格指南。遵守这个风格指南将帮助你在不同项目编写一贯不变的干净代码。同时,遵守PEP8的程序员会更轻松地浏览其它遵守PEP8的代码库。
类型暗示¶
类型暗示是在Python 3.5(通过PEP 484)添加的一种允许用户注释函数定义来指出函数输入和输出的对象类型的语法。比如说,让我们定义一个函数来数字符串中元音数并使用类型暗示来注释函数的签名吧。
# 用类型暗示注释过的函数签名
def count_vowels(x: str) -> int:
"""返回 `in_string` 中元音的数量"""
vowels = set("aeiouAEIOU")
return sum(1 for char in x if char in vowels)
在这里,我们“暗示”了 x 应为字符串类型的对象,以及函数会返回整数类对象。注释过的有着任意多位置参数和默认值参数的函数的一般形式如下:
def func_name(arg: <type>, [...], kwarg: <type> = <value>, [...])) -> <type>:
请注意,每个参数名后都跟着一个冒号和作为类型暗示的类型对象。函数的返回类型则在签名的后括号之后;它前置一个箭头 -> 并后置标记函数签名结尾的冒号。你可以使用相同的语法来注释类定义中的方法。
让我们修改 count_vowels 来添加一个允许用户可选地将 ‘y’ 视作元音的默认值参数。
# 默认值参数的类型暗示
def count_vowels(x: str, include_y: bool = False) -> int:
"""返回 `in_string` 中元音的数量"""
vowels = set("aeiouAEIOU")
if include_y:
vowels.update("yY")
return sum(1 for char in x if char in vowels)
在这里,我们暗示了 include_y 会期待布尔类对象,以及它的默认值为 False。花些时间习惯 include_y: bool = False 的形式很重要。可能一开始这有点难读。请记住,: bool 在这里是类型暗示,而 = False 提供了默认参数。这两个语句的顺序并不可以互换——类暗示必须立即跟随变量名字。
Python 3.6通过PEP 526加入了一个用来注释代码中独立变量的语法。比如说,假设你在代码中初始化一个将储存偶数的列表,你可以如下注释这个变量:
# 使用类暗示来注释变量
from typing import List, Set
names: Set[str] = []
odd_numbers: List[int] = []
这允许我们记录这个空列表将会储存整数。你也可以注释一个变量而不提供初始值。
# 注释一个函数但不提供值
max_num: int
请注意,这种变量注释语法在Python 3.6之前的版本并不合法,而函数注释语法在Python 3.5之前的版本并不合法。PEP 483提供了一个正式的类型暗示理论。
这能做什么?(什么都不能)¶
从Python直译器的角度来看,类型暗示对你的代码没有任何除了添加说明文档以外的意义。也就是说,Python不会根据你的类型暗示提供任何强制的类型检查。这和其它如C++的需要为函数提供由编译器履行的输入和输出类型强类型(strongly-typed)语言对比鲜明。
的确,在Python中我们可以无视注释的类型暗示随意提供任何参数。与其提供一个字符串,让我们向以上定义的 count_vowels 函数提供一个空列表吧。
# 类型暗示并不会真的执行类型检查。在这里,我们输入了一个空列表,而不是
# 字符串,但是没有导致任何警告或错误。
>>> count_vowels([])
0
请注意,我们的函数并不在乎我们违反了我们类型暗示保证输入的是字符串这一事实。它开心地循环这个空列表并求其零个成员的和,并返回 0。这也是为什么这些注释仅仅叫做类型暗示,而不是类型要求。
虽然CPython直译器就在Python 3的生命周期中将永远不会要求或强制使用类型暗示,但是有第三方模组和工具来使用类型暗示。那些第三方功能使得类型暗示值得使用。如PyCharm和VSCode的IDE可以使用类型暗示来达到很棒的功能。它们会在你向函数输入不符合类型暗示的对象时警告你,且它们会使用这些类型暗示来记录函数返回的对象。
比如说,假设我们在我们正在开发的一个代码模组中使用 count_vowels 函数,且我们错误地认为函数的输出是一个字符串并试图将其大写化。我们的IDE将会注意到我们试图大写一个整数并如此警告我们:
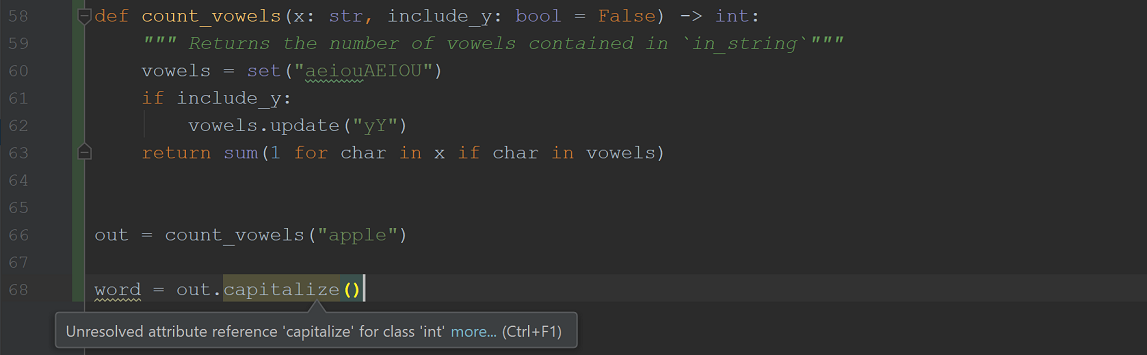
这相比运行代码,遭遇错误,阅读错误,并修正它的流程所花的时间少很多。我们可以立刻看到被标记出的冲突。事实上,我们可能永远都不会产生这个错误,因为我们的IDE会自动显示一列表的整数方法,而不是字符串方法。这很可能会直接纠正我们的错误理解。
你不会需要花多久就会通过IDE感受到类型暗示的好处。这将通过告诉你正在操作的对象类型来提升你编写代码的速度,并在你犯错的时候立刻提醒你。
最后,我们来花一些时间安利一下mypy项目。它根据你的代码的类型暗示进行静态的类型检查。也就是说,mypy将会自动遍历你的代码并通过检查对象的标注或推测出的类型来检测代码中的类型冲突(如试图大写化一个整数),指出可能的bug。在大规模代码库中这个工具极其有用。像Dropbox这样的公司经常使用mypy来在检测它们代码中的冲突来避免运行时的错误。在你作为一名Python开发者逐渐成熟并编写越来越复杂的项目的过程中,请记住mypy。
使用 typing 模组¶
虽然我们可以使用Python的内置类型对象(如 list 和 dict)来进行类型暗示,标准库的typing模组提供了可以用来创建更加描述性的暗示的对象。比如说,假设我们想编写一个接受整数列表的函数,使用内置的 list 对象不能标示这个列表应该存储整数。但是,使用 typing.List 则指出更完善的类型暗示语法:typing.List[int] 标示了“整数列表”。熟悉 typing 模组是编写好类型暗示的第一步。
以下是对 typing 模组中最重要的一些成员的总结,以及使用它们的一些例子。
Any¶
暗示:任何对象类
Union[<type>, <type>]¶
暗示:任何两种对象类型
例:暗示整数或布尔值:
Union[int, bool]
Optional[<type>]¶
暗示:
<type>或None,但None是默认值例:暗示一个默认为
None的值,但如果不是默认值就是一个字符串:Optional[str]
None¶
暗示:对象
None
List[<type>]¶
暗示:包含任何数量的某种对象的列表
例:
暗示字符串列表:
List[str]暗示字符串和整数列表:
List[Union[str, int]]暗示任何成员的列表的列表:
List[List[Any]]或List[List]
Tuple[<type>, ...]¶
暗示:包含某数量的某些类型的对象的元组。
...可以用来标示元组有着任意数量的对象例:
暗示包含一个字符串和一个布尔值的元组:
Tuple[str, bool]暗示包含任意多整数的元组:
Tuple[int, ...]
Set[<type>]¶
暗示:包含任意某类对象的集
例:
暗示浮点数集:
Set[float]暗示(包含两个整数的)元组集:
Set[Tuple[int, int]]
Dict[<key-type>, <value-type>]¶
暗示:将某类的键对应某类的值的词典
例:
暗示字符串对应整数的词典:
Dict[str, int]暗示任何可哈希对象对应布尔值的词典:
Dict[Hashable, bool]
Callable[[<arg-type>], <output-type>]¶
暗示:任何接受某些类型的参数并返回某类的可调用对象(如参数或方法)
例:
暗示接受一个字符串和一个整数并返回
None的函数:Callable[[str, int], None]暗示一个接受任意参数并返回布尔值的方法:
Callable[..., bool]
Literal[<value>, ...]¶
暗示:具体准确的值
例:
暗示接受整数
1:Literal[1]暗示接受字符串
"sum"或字符串"mean":Literal["sum", "mean"]暗示接受列表
[1, 2]或字符串"abc":Literal[[1, 2], "abc"]
兼容性:
Literal类型暗示是在Python 3.8版本加入的——你无法在之前版本的Python中使用它。
作为一个例子,让我们设一个接受如下的函数:
包含学生成绩的词典,其将名字(字符串)对应到成绩(浮点数列表)
计算数字列表的统计数据的函数
想要计算统计数据的学生名字列表,默认为所有学生
并返回元组列表,每个元组包含学生的名字和ta的统计数据。
from typing import Dict, Callable, Optional, List, Tuple, Any
def compute_student_stats(grade_book: Dict[str, List[float]],
stat_function: Callable[[List[float]], Any],
student_list: Optional[List[str]] = None) -> List[Tuple[str, Any]]:
"""计算学生成绩的自定义统计数据。
Parameters
----------
grade_book : Dict[str, List[float]]
所有学生成绩的词典(名字 -> 成绩)。
stat_function: Callable[[List[float]], Any]
计算每个学生成绩的统计数据的函数。
student_list : Optional[List[str]]
需要计算统计数据肚饿学生名字列表。
函数会默认计算成绩簿中所有学生的统计数据。
Returns
-------
List[Tuple[str, Any]]
每个学生的名字和统计数据元组。
"""
if student_list is None: # 默认所有学生
student_list = sorted(grade_book) # 迭代词典的键
return [(name, stat_function(grade_book[name])) for name in student_list]
(请注意,我们同时添加了一个细致的NumPy风格docstring;我们将会在接下来的小节中仔细讨论这个说明文档风格)。
在这里有应注意几个细节。首先,我们没有对 stat_function 返回的对象类型没有进行任何假设。它可能会返回单个浮点数的平均值,或包含平均值,中间值,最频繁出现值等等的元组。因此,我们说明它的返回类型是 Any;这在我们函数的返回类型中也有显示:List[Tuple[str, Any]]。和我们马上要进行的讨论呼应,你应该在类型暗示尽可能细致的前提下做到不丢失任何通用性。然后,Optional[List[str]] 用来标记 student_list 的默认值是 None,但如果不是默认值我们向其输入一个字符串列表。这比起等值的暗示
Union[None, List[str]] 更加易读,而且它表达了默认值是 None 这个事实。
如果你定义了自己的类型(既类),你可以在暗示中直接提供这个类对象。这类型暗示了某个变量将接受该类型的一个实例。如果你遇到了想要暗示类对象本身(而不是其实例)的稀少情况,你可以使用 typing.Type 来表达这一点。
让我们编写一个简单的例子来演示这些片。我们将定义我们的 Dog 类并编写一个接受 Dog 类对象(类型暗示为 Type[Dog])的函数。该函数将创建几个 Dog 类的实例(类型暗示为 Dog)并将它们放入列表中返回。
# 类型暗示自定义类
from typing import List, Type
class Dog:
def __init__(self, name):
self.name = name
# cls 期望为类对象 `Dog` 本身
# 这个函数返回一列表的 `Dog` 类型实例
def list_famous_dogs(cls: Type[Dog]) -> List[Dog]:
return [cls(name) for name in ["Lassie", "Shadow", "Air Bud"]]
你也可以在代码中创建类型代名词(type alias)并在注释中使用。比如说,如果你将经常使用有着五个 Dog 实例的元组,你可以定义一个代名词来使得你的类型暗示更加简短:
# 创建类型的代名词
Pack = Tuple[Dog, Dog, Dog, Dog, Dog]
def find_alpha(dogs: Pack) -> Dog:
...
第三方模组定义的对象类型,如NumPy的N维数组和我们自己的自定义类行为一样;直接在类型暗示标注中提供类对象就行了:
# 类型桉树numpy的N维数组
import numpy as np
def custom_dot_product(x: np.ndarray, y: np.ndarray) -> float:
return float(np.sum(x * y))
早晚有一天,像NumPy这样的流行的第三方模组将会贡献它们自己的类型模组来帮助你提供更加保真的类型暗示,如数据类型和数组形状。NumPy开发者正在为此工作。
经验:
Python的 typing 模组包含了用来创建描述性类型暗示的对象。比如说,虽然 list 只能用来类型暗示一个列表,typing.List[str] 描述了一个字符串列表。你也可以使用它们来为在代码中重复使用的复杂类型暗示创建简短的代名词。
一般而言,你可以使用类对象来进行类型暗示,且其暗示了一个变量将为该类的一个实例。比如说,numpy.ndarray 暗示了一个变量将接受一个N维数组。
编写好的类型暗示¶
你应该尽量编写通过鸭子测试的代码:如果你的函数期待一个鸭子,那么暗示一个走起来像鸭子,叫起来像鸭子,等等的东西。这将帮助你避免编写太过狭隘并因此不符合Python风格的类型暗示。
具体来讲,让我们复习一下我们的 count_vowels 函数:
def count_vowels(x: str, include_y: bool = False) -> int:
"""返回 `x` 中元音的数量"""
vowels = set("aeiouAEIOU")
if include_y:
vowels.update("yY")
return sum(1 for char in x if char in vowels)
仔细看 x 在函数中如何使用。我们用for循环迭代 x——这没有任何仅限于字符串的功能。我们向这个函数可以输入一个字符串,元组,列表,或任何支持迭代的对象,而它都会开开心心地计算 x 中的元音数。
# `count_vowels` 可以操作任何字符串可迭代物
>>> count_vowels("apple")
2
>>> count_vowels(['a', 'p', 'p', 'l', 'e'])
2
>>> count_vowels(('a', 'p', 'p', 'l', 'e'))
2
>>> count_vowels({'a', 'p', 'p', 'l', 'e'})
2
类型暗示 x 为 str 就太过限制且非Python风格了。让我们修改类型暗示使其更加包容。
typing 模组提供了所谓的抽象基类 Iterable,其为代表任何支持迭代的类的一般类型。因此,我们可以通过使我们的类型暗示更标准化来提升它的描述性。这将包含我们上面演示中的所有使用方法。
from typing import Iterable
def count_vowels(x: Iterable[str], include_y: bool = False) -> int:
"""返回 `x` 中元音的数量"""
vowels = set("aeiouAEIOU")
if include_y:
vowels.update("yY")
return sum(1 for char in x if char in vowels)
(如果我们想要完全的标准化,我们可以暗示 Iterable[Hashable],因为我们依赖 x 中的成员的可哈希特征来检查它们是否在元音集中。你应该决定你的鸭子要有多抽象)。
复习Python集合的抽象基类(abstract base class(abc))很重要(是的,我在建议你复习你的abc——译者注:abc也可以指小学生学的字母表)。这将帮助你一般性地根据对象的特殊方法分类它们。两个最常用的abc是 Iterable:任何支持迭代协议的类,和 Sequence:任何有着长度(通过 __len__)和支持获取成员语法(通过
__getitem__)的集合。
阅读理解:类型暗示
阅读以下函数并使用类型暗示标记它的签名。尝试让你的类型暗示足够标准化。
def get_first_and_last(x):
"""返回 `x` 的第一和最后一个成员。函数将假设 `x` 非空。
"""
return (x[0], x[-1])
以下是一些使用该函数的例子。请使你的类型暗示支持这些多样的使用方法。
>>> get_first_and_last("hello")
('h', 'o')
>>> get_first_and_last([0, 1, 2, 3])
(0, 3)
>>> get_first_and_last((True, False))
(True, False)
经验:
在类型暗示时太过严苛是不符合Python风格的做法。Python灵活地处理类型分类——它使用鸭子类型分类——且我们的类型暗示也应该如此。每当可以的时候使用抽象基类来提供某种变量类型的合理规则。
说明文档风格¶
Davis King,一个多产又有才的开源开发者,是dlib C++库的创造者。在库如机器学习算法的主要功能中,David将其说明文档列为第一个和最重要的功能。事实上,他如此评论dlib:
我认为说明文档是这个库最重要的组件。 所以如果你发现任何东西没有说明文档,不清楚,或有着过时的说明文档,告诉我,我将修好它。
如此重视说明文档是一个很聪明地做饭。在本小节中,我们将学习两个流行的Python docstring风格的规格:NumPy规格和Google规格。两个规格都是对PEP 257提出的基础docstring的强大拓展,且它们都对记录变量类型有着极大的重视。
PLYMI在阅读大部分时候(除了在我们试图使函数简短时)都使用了NumPy风格的docstring。最终而言这只是一个风格/美观上的选择。总而言之,这里最重要的经验是去选择一个说明文档风格,学习它,并忠诚地使用它。再次重申一次,我们很难夸张使用清晰和协调的说明文档有多重要。它将帮助你的代码的编写过程。它将允许用户使用和甚至对你的代码做贡献,并将保证你的辛苦工作的长命。
NumPy说明文档¶
NumPy说明文档风格在在这里完整地列出。在这里我强烈建议你完整阅读这个列表。我们将在这里忽略一些细节来保证阅读的简单度并避免重复以上文档中的内容。我们将专注于为函数编写说明文档的规则,但请注意它们也提供了为类和模组编写说明文档的规则。
函数的docstring分为几个部分。大部分这些部分都由一个头行,如“Parameters”,和一行折线限定。
Parameters
----------
一个docstring至少应有:
一个简短的单行函数功能描述。
一个更长的函数总结,其为提供更多细节描述。
一个
Parameters部分,其提供了输入参数的类型以及它们的描述。(如果你的函数不接受参数,那这一部分也就没有必要了)。一个
Returns部分(如果是生成器的话是Yields),其提供了函数返回对象的细节。(如果你的函数永远返回sNone,那这一部分也就没有必要了)。
你也可以添加额外的,可选的部分来提升你的说明文档:
一个
Notes部分。你可以用它提供函数额外的注释,如函数所使用的算法。你也可以在这里提供数学公式并列出参考资料。一个
References部分。你可以用它来记录任何在“Notes”部分参考的资料。你很少会需要在docstring中引用参考资料。一个
Examples部分,其含有演示如何使用你的函数的命令行风格的代码(类似于你在PLYMI中见到的代码片段)。
上文提供的正式说明文档风格文件中列出了其它的更加少见或技术性的部分可供你添加。
以下函数有着一个包含以上所有部分的docstring。
def pairwise_dists(x: np.ndarray, y: np.ndarray) -> np.ndarray:
"""计算 ``x`` 和 ``y`` 每行对之间的距离。
返回形状为 (M, N) 的 ``x`` 中M行和 ``y`` 中
N行的欧氏距离数组。
Parameters
----------
x : numpy.ndarray, shape=(M, D)
可选的对 ``x`` 的介绍
y : numpy.ndarray, shape=(N, D)
可选的对 ``y`` 的介绍
Returns
-------
numpy.ndarray, shape=(M, N)
距离对
Notes
-----
本函数使用了内存高效的矢量化实现。细节可以在 [1]_ 中找到。
References
----------
.. [1] Soklaski, R. (2019, Jan 21). Array Broadcasting.
Retrieved from https://www.pythonlikeyoumeanit.com
Examples
--------
计算形状为 (3, 3) 的数组的行和形状为 (2, 3) 的数组的行之间
的距离对。
>>> import numpy as np
>>> x = np.array([[1., 2., 3.],
... [4., 5., 6.],
... [7., 8., 9.]])
>>> y = np.array([[1., 2., 3.],
... [4., 5., 6.]])
>>> pairwise_dists(x, y)
array([[ 0. , 5.19615242],
[ 5.19615242, 0. ],
[10.39230485, 5.19615242]])
"""
...
请注意,我们在docstring的 Parameters 和 Returns 部分提供了类型信息,虽然这重复了函数签名中的类型暗示——在docstring中也有这个信息是很有用的。这是一个提供正式类型暗示中缺失的有关信息的好地方。比如说,我们在这些部分的类型旁边添加了形状的信息。
在docstring中,变量名应用在两边分别用两个 ` 符号包围,如 ``x``。请注意,包含一个 Examples 部分为创建高质量的说明文档极其有帮助。本文建议你在你的代码中活用多用范例部分。
以下是另外一个符合NumPy风格的范例docstring,但它没有 Notes 和 References 部分:
def compute_student_stats(grade_book: Dict[str, Iterable[float]],
stat_function: Callable[[Iterable[float]], Any],
student_list: Optional[List[str]] = None) -> List[Tuple[str, Any]]:
"""计算学生成绩的自定义统计数据。
对每个学生的成绩列表调用 ``stat_func``,并将结果作为名字-数据的元组
储存到一个列表中。
Parameters
----------
grade_book : Dict[str, List[float]]
所有学生成绩的词典(名字 -> 成绩)。
stat_function: Callable[[Iterable[float]], Any]
用来计算每个学生成绩的统计数据的函数。
student_list : Optional[List[str]]
需要计算统计数据的学生名字列表。函数将默认计算所有成绩簿中
学生的统计数据。
Returns
-------
List[Tuple[str, Any]]
每个学生的名字-数据元组。
Examples
--------
>>> from statistics import mean
>>> grade_book = dict(Bruce=[90., 82., 92.], Courtney=[100., 85., 78.])
>>> compute_student_stats(grade_book, stat_function=mean)
[('Bruce', 88.0), ('Courtney', 87.66666666666667)]
"""
...
Google说明文档风格¶
Google说明文档的完整规则可以在这里找到;它是完整Google Python风格指南的一部分。在这里描述的docstring风格对比NumPy的规格相对简短。它包含了以下部分:
一个简短的单行函数描述。
一个更长的函数总结,其为提供更多细节描述。
一个
Args部分,其细致提供了函数的输入参数的类型和描述(如果你的函数没有参数,那么这个部分也没有必要了)。一个
Returns部分(如果是生成器的话是Yields),其细致描述了函数返回的对象(如果你的函数永远返回None,那么这个部分也没有必要了)。
如果你的函数在已知情况下引发错误(raises an exception)的话,你也可以添加一个 Raises 部分。
让我们使用Google的风格来重写 pairwise_dists 和 compute_student_stats 的docstring。
def pairwise_dists(x: np.ndarray, y: np.ndarray) -> np.ndarray:
"""计算 ``x`` 和 ``y`` 每行对之间的距离。
返回形状为 (M, N) 的 ``x`` 中M行和 ``y`` 中
N行的欧氏距离数组。
Args:
x (numpy.ndarray) : 一个形状为 (M, D) 的数组
y (numpy.ndarray) : 一个形状为 (N, D) 的数组
Returns:
(numpy.ndarray): 一个形状为 (M, N) 的距离对数组
"""
...
def compute_student_stats(grade_book: Dict[str, Iterable[float]],
stat_function: Callable[[Iterable[float]], Any],
student_list: Optional[List[str]] = None) -> List[Tuple[str, Any]]:
"""计算学生成绩的自定义统计数据。
对每个学生的成绩列表调用 ``stat_func``,并将结果作为名字-数据的元组
储存到一个列表中。
Args:
grade_book (Dict[str, List[float]]): 所有学生成绩的词典
(名字 -> 成绩)。
stat_function (Callable[[Iterable[float]], Any]): 用来
计算每个学生成绩的统计数据的函数。
student_list (Optional[List[str]]): 需要计算统计数据的学生
名字列表。函数将默认计算所有成绩簿中学生的统计数据。
Returns
(List[Tuple[str, Any]]): 每个学生的名字-数据元组。
"""
...
请注意,本风格创建简短,但有时因为每个部分中的缩进而横向拥挤的docstring。
同时,帮助你自动从Python的docstring生成HTML说明文档页面的Napolean项目已经拓展了Google的规格来对应NumPy风格的部分。Napolean版本的NumPy和Google的docstring风格可以在这里找到。这个资源也包含了很多有用的模组和类的范例docstring。
经验:
花一些时间来复习NumPy和Google的docstring风格,选择其一,并在为你的代码编写说明文档时遵守它。如果你打算和其它人一起合作,那么了解他们是否已经选择了一个说明文档风格。
说明文档工具:
Sphinx是一个流行且极其强大的工具。它通过分析你代码中的docstring来为你生成HTML说明文档。Python,NumPy,和几乎所有重要的第三方Python模组都使用Sphinx来发布它们的说明文档页面。Napolean和numpydoc是允许Sphinx分析并好看地渲染遵守NumPy和Google的风格的docstring的Sphinx拓展。
custom_inherit是一个继承和合并docstring的轻量工具。它提供了合并docstring不同部分的强大功能并原生支持NumPy和Google风格的docstring。它也支持自定义的说明文档风格。
官方说明文档链接¶
阅读理解答案:¶
类型暗示:解
以下是一个注释过的 get_first_and_last 版本:
from typing import Sequence, Tuple, Any
def get_first_and_last(x: Sequence[Any]) -> Tuple[Any, Any]:
"""返回 `x` 的第一和最后一个成员。函数将假设 `x` 非空。
"""
return (x[0], x[-1])
这个函数仅仅要求 x 可以被索引。参考Python集合的抽象基类列表,Sequence 是最简单的支持 __getitem__ 语法的抽象基类。确实,如我们所见,这是一个通用于所有Python序列类型的属性。最后,请注意,我们对 x 的成员不进行任何假设,所以我们使用了通用的 Any 类型。