生成器和理解表达式¶
注:
本文各处的阅读理解练习旨在帮助你练习使用文章中的知识点。练习题的答案可以在本页结尾找到。
生成器简介¶
现在,让我们介绍一种重要的对象,生成器(generator)。它允许我们生成(generate)任意长度的序列,并不需要同时在内存中存储其所有的成员。
定义:
生成器是一种特殊的迭代器。它存储如何顺序生成新成员的指示以及迭代的内态。它在收到请求后会一次一个生成其成员。
请回忆列表同时存储其所有成员这一事实;你可以通过迭代访问其任何成员。与列表不同的是,生成器不存储任何成员。它存储如何生成新成员的指示以及它迭代的内态;这意味着如果生成器已经生成了第二个成员,它会知道这一点并在下次迭代时生成第三个成员。
以上太长不读的版本就是说你可以用生成器来生成长的成员序列,而并不需要将它们全部同时储存在内存中。
range 生成器¶
range 是一个很常用的内置生成器。它接受以下输入值:
“start”(包括数字本身,默认为0)
“stop”(不包括数字本身)
“step”(默认为1)
并以此在迭代时生成对应的整数序列(从start到stop,步距为step)。看看以下的 range 使用范例:
# start: 2(包含)
# stop: 7(不包含)
# step: 1(默认)
for i in range(2, 7):
print(i)
# 打印:2.. 3.. 4.. 5.. 6
# start: 1(包含)
# stop: 10(不包含)
# step: 2
for i in range(1, 10, 2):
print(i)
# 打印:1.. 3.. 5.. 7.. 9
# 一个很常见的使用范例!
# start: 0(默认,包含)
# stop: 5(不包含)
# step: 1(默认)
for i in range(5):
print(i)
# 打印:0.. 1.. 2.. 3.. 4
因为 range 是一个生成器,指令 range(5) 仅仅只会存储用来生成数字0-4序列的指示。这和会同时在内存中存储所有数字的列表 [0, 1, 2, 3, 4] 不同。对短列表而言,这样做节省的内存可能很不可观,但是在处理长序列这就很重要了。以下的图表对比了使用 range 来定义一个生成数字序列 \(0-N\) 和使用列表存储该序列的内存使用情况:
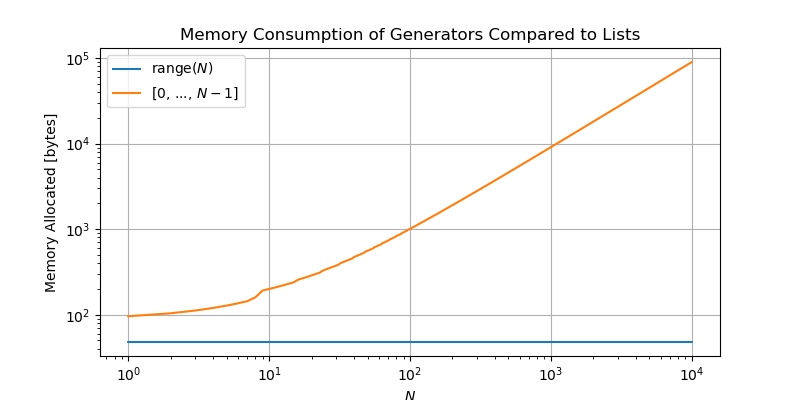
根据上文对生成器的讨论,你应该理解为什么定义 range(N) 使用的内存和 \(N\) 的大小无关,而列表使用的内存根据 \(N\) 线性增长(假设 \(N\) 比较大)。
经验:
range 是一个内置的生成器,其生成整数序列。
阅读理解:使用 ``range``:
在一个for循环中使用 range 来打印数字10-1(按此顺序)。
创建你自己的生成器:生成器理解¶
Python提供了一个轻便的用一行代码定义简单生成器的语法;这种表达式叫做生成器理解(generator comprehension)。以下语法极其有用,且在Python代码中非常常见:
定义:
语法 (<expression> for <var> in <iterable> [if <condition>]) 描述了生成器理解的一般形式。这将创建一个生成器,其生成成员的指示由括号中的语句提供。
用伪代码来写,以下代码
(<expression> for <var> in <iterable> if <condition>)
的长形式为:
for <var> in <iterable>:
if bool(<condition>):
yield <expression>
以下的表达式定义了一个0-99之间所有偶数的生成器:
# 当被迭代时,`even_gen` 将生成 0.. 2.. 4.. ... 98
even_gen = (i for i in range(100) if i%2 == 0)
生成器中的 if <condition> 句段是可选的。以下的生成器理解
(<expression> for <var> in <iterable>)
对应着:
for <var> in <iterable>:
yield <expression>
比如说:
# 当被迭代时,`example_gen` 将生成 0/2.. 9/2.. 21/2.. 32/2
example_gen = (i/2 for i in [0, 9, 21, 32])
for item in example_gen:
print(item)
# 打印:0.0.. 4.5.. 10.5.. 16.0
<expression> 可以是任何合法的返回单个对象的单行Python代码:
((i, i**2, i**3) for i in range(10))
# 会生成:
# (0, 0, 0)
# (1, 1, 1)
# (2, 4, 8)
# (3, 9, 27)
# (4, 16, 64)
# (5, 25, 125)
# (6, 36, 216)
# (7, 49, 343)
# (8, 64, 512)
# (9, 81, 729)
这意味着 <expression> 甚至可以使用单行的if-else语句!
(("apple" if i < 3 else "pie") for i in range(6))
# will generate:
# 'apple'..
# 'apple'..
# 'apple'..
# 'pie'..
# 'pie'..
# 'pie'
经验:
生成器理解是Python单行定义生成器的语法。这个语法对于编写简单和易读的代码是不可替代的。
注:
生成器理解并不是唯一定义Python生成器的方法。你可以用类似定义函数(我们会在后文讨论)的方法定义生成器。详见本节Python官方教程来深入了解生成器。
阅读理解:编写生成器理解:
使用生成器理解,定义一个会生成以下序列的生成器:
(0, 2).. (1, 3).. (2, 4).. (4, 6).. (5, 7)
注意 (3, 5) 并不在序列中。
迭代该生成器并打印其内容以确认你的答案。
存储生成器¶
就像 range 一样,利用生成器理解来定义生成器不会进行任何运算或使用除了储存生成数据序列的规则之外的内存。请注意我们打印此生成器时会发生什么:
# 将会生成 0, 1, 4, 9, 25, ..., 9801
>>> gen = (i**2 for i in range(100))
>>> print(gen)
<generator object <genexpr> at 0x000001E768FE8A40>
此输入仅仅显示 gen 在内存位置 0x000001E768FE8A40 存储了一个生成器;这仅仅是存储生成平方数指示的内存位置。gen 在我们迭代它之前并不会生成任何结果。因此,你无法像查看列表和其它序列一样来查看生成器。以下的代码不合法:
# 以下的行为**不合法**
>>> gen = (i**2 for i in range(100))
# 检查生成器的长度
>>> len(gen)
TypeError: object of type 'generator' has no len()
# 索引生成器
>>> gen[2]
TypeError: 'generator' object is not subscriptable
以上规则唯一的例外就是 range 生成器。你可以对它进行以上的操作。
消耗生成器¶
我们可以将生成器输入到任何接受可迭代数的函数中。比如说,我们可以将 gen 输入到内置的 sum 函数中。该函数会求可迭代物成员的和:
>>> gen = (i**2 for i in range(100))
>>> sum(gen) # 求和:0 + 1 + 4 + 9 + 25 + ... + 9801
328350
这在从来不在内存中储存整个数字序列的情况下计算以上数据序列的和。事实上,在任何一轮迭代中,Python只需要存储两个数字:到这一步为止的和以及下一步要加的数字。
如果我们第二次执行这个命令:
# 求和...为空!
# `gen` 已经被消耗了!
>>> sum(gen)
0
你可能惊讶于sum现在返回0这一事实。这是因为当生成器被完全迭代后它会消耗殆尽。你必须重新定义该生成器来再次迭代它;幸运得是,定义一个生成器花的资源很少,所以你不需要去担心资源需求。
你也可以检查某对象是否属于生成器的一部分,但这么做会消耗(consume)这个生成器:
# 检查某个对象是否为生成器成员会消耗生成器
# 直到对象被找到(如果对象不为生成器成员,
# 那整个生成器都会被消耗)
>>> gen = (i for i in range(1, 11))
>>> 5 in gen # 前5个成员被消耗
True
# 1-5 已经不在 `gen` 中了
# 因此这个检查会消耗整个生成器!
>>> 5 in gen
False
>>> sum(gen)
0
经验:
生成器只能被迭代一次。在这之后它会被消耗殆尽。你必须要重新定义新的生成器来再次迭代。
连锁理解¶
因为生成器是可迭代物,你可以将它们输入到另一层的生成器理解中。也就是说你在“连锁”(chain)它们。
# 连锁两个生成器理解
# 生成 400.. 100.. 0.. 100.. 400
>>> gen_1 = (i**2 for i in [-20, -10, 0, 10, 20])
# 迭代 `gen_1`,除去任何绝对值大于150的值
>>> gen_2 = (j for j in gen_1 if abs(j) <= 150)
# 计算 100 + 0 + 100
>>> sum(gen_2)
200
这等值于:
total = 0
for i in [-20, -10, 0, 10, 20]:
j = i ** 2
if j <= 150:
total += j
# `total` 现在是200
直接使用生成器理解¶
Python支持你直接将生成器理解输入进使用可迭代物的函数。这将使你的代码极其可读易懂。比如说:
>>> gen = (i**2 for i in range(100))
>>> sum(gen)
328350
可以被简化为:
>>> sum(i**2 for i in range(100))
328350
如果你想要你的代码来计算有限的谐波系列:\(\sum_{k=1}^{100} \frac{1}{n} = 1 + \frac{1}{2} + ... + \frac{1}{100}\),你可以直接写:
>>> sum(1/n for n in range(1, 101))
5.187377517639621
这方便的语法可以在任何使用可迭代物的函数中作为输入,如 list 函数和 all 函数:
# 将生成器表达式直接输入进使用可迭代物的函数中
>>> list(i**2 for i in range(10))
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> all(i < 10 for i in [1, 3, 5, 7])
True
>>> ", ".join(str(i) for i in [10, 200, 4000, 80000])
'10, 200, 4000, 80000'
经验:
你可以将生成器理解语句直接作为任何需要可迭代物的函数输入。
阅读理解:直接使用生成器理解:
在一行内计算0-100之间所有奇数之和。
使用 next 迭代生成器¶
内置函数 next 允许我们手动“请求”生成器(或任何迭代器(iterator))的下一个成员。对一个消耗殆尽的迭代器调用 next 会导致 StopIteration 信号。
# 使用 `next` 消耗迭代器
>>> short_gen = (i/2 for i in [1, 2, 3])
>>> next(short_gen)
0.5
>>> next(short_gen)
1.0
>>> next(short_gen)
1.5
>>> next(short_gen)
StopIteration
Traceback (most recent call last)
<ipython-input-5-ed60a54ccf0b> in <module>()
----> 1 next(short_gen)
StopIteration:
这方便你在不使用for循环的情况下获取生成器或任何迭代器的成员。
可迭代物 vs. 迭代器¶
本小节并不是理解本资源的关键内容。包含本小节的目的是为了不误导已经对Python有一些了解的读者。本小节内容比较深入,请随意跳过……
让我们来解释清楚一些易混的术语:可迭代物和迭代器是不一样的。
一个迭代器对象存储着迭代过程当前的内态,并在收到通过 next 提出的请求时顺序“提供”(yield)它的成员,直到它消耗殆尽。像我们所见,生成器是迭代器的一种。请注意,每一个迭代器都是可迭代物,但不是每一个可迭代物都是迭代器。
一个可迭代物是任何可以被迭代的对象,但它不一定有着迭代器全部的功能。比如说,序列(如列表,元组,和字符串)和其它容器(如词典和集)并不会存储其迭代过程的内态。因此你不能直接对其调用 next:
# 列表是可迭代物,但*不是*迭代器——你不能对其调用 `next`。
>>> x = [1, 2, 3]
>>> next(x)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-19-b9d20096048c> in <module>()
----> 1 next([1,2])
TypeError: 'list' object is not an iterator
为了迭代如列表这样的可迭代物,你必须先将其输入到内置的 iter 函数中。这个函数会返回该列表的一个迭代器,其存储着它迭代的内态以及提供列表每一个成员的指示:
# 任何可迭代物都可以被输入进 `iter` 中
# 来得到该对象的一个迭代器
>>> x = [1, 2, 3]
>>> x_it = iter(x) # `x_it` 是一个迭代器
>>> next(x_it)
1
>>> next(x_it)
2
>>> next(x_it)
3
所以说列表是可迭代物但不是迭代器。这一点和元组,字符串,集,和词典一样。
每当你for循环一个如列表的迭代器时,Python其实都会在“幕后”创建一个迭代器。它将可迭代物输入进 iter 中,并在for循环每轮迭代时对返回的迭代器调用 next。
列表和元组理解¶
因为使用生成器理解来初始化列表的流程极其有用,Python专门为其定义了专门的语法,叫做列表理解(list comprehension)。列表理解是一种创建列表的语法,和生成器理解语法完全类似:
[<expression> for <var> in <iterable> {if <condition}]
比如说,如果我们想要创建成员为平方数的列表,我们可以直接编写:
# 简单的列表理解
>>> [i**2 for i in range(10)]
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
这将创建和对生成器理解输入调用 list 函数一样的结果。但是,使用列表理解比将生成器理解输入到 list 中稍微更高效一点。
让我们来体会一下列表理解的实惠之处。以下代码将在一个列表中储存包含字母“o”的字符串:
words_with_o = []
word_collection = ['Python', 'Like', 'You', 'Mean', 'It']
for word in word_collection:
if "o" in word.lower():
words_with_o.append(word)
你可以使用列表理解来将以上代码在一行中实现:
>>> word_collection = ['Python', 'Like', 'You', 'Mean', 'It']
>>> words_with_o = [word for word in word_collection if "o" in word.lower()]
>>> words_with_o
['Python', 'You']
你也可以用理解语句来创建元组,但是你必须要使用 tuple 构造器来做到这一点,因为括号已经为生成器理解保留了。
# 使用理解表达式来创建元组
>>> tuple(i**2 for i in range(5))
(0, 1, 4, 9, 16)
经验:
理解语句是对创建简单或复杂的列表或元组都极其有用的语法。
嵌套理解语句¶
你可以在一个理解表达式中嵌套(nest)另外一个理解表达式,但请注意不要滥用这一功能。
# 嵌套列表理解。
# 这创建了一个大小为3x4,内容为0的的“矩阵”(存有多个列表的列表)。
>>> [[0 for col in range(4)] for row in range(3)]
[[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]
阅读理解:列表理解:
使用列表理解来的创建一个包含100个字符串“hello”的列表。
阅读理解:高级的列表理解:
使用单行的 if-else 语句(在本模组前文讨论过)以及列表理解来创建以下列表:
['hello',
'goodbye',
'hello',
'goodbye',
'hello',
'goodbye',
'hello',
'goodbye',
'hello',
'goodbye']
阅读理解:元组理解:
使用元组理解来提取字符串中由逗号隔开的数字,并将它们转化成一个浮点数元组。比如说,"3.2,2.4,99.8" 应被转化成 (3.2, 2.4, 99.8)。你应该会想要使用内置的字符串函数str.split。
阅读理解:翻译for循环:
使用列表理解来复制以下代码的功能。
# 跳过所有非小写字母(包括标点符号)
# 如果小写字母是“o”,在列表结尾添加1
# 如果小写字母不是“o”,在列表结尾添加0
out = []
for i in "Hello. How Are You?":
if i.islower():
out.append(1 if i is "o" else 0)
阅读理解:内存效率:
以下两个表达式的效率有任何区别么?
# 将生成器理解输入到 `sum` 中
sum(1/n for n in range(1, 101))
# 将列表理解输入到 `sum` 中
sum([1/n for n in range(1, 101)])
以上有一个表达式优于另外一个吗?为什么?
阅读理解答案:¶
使用 ``range``:解
# start=10,stop=0(不包含),step-size=-1
>>> for i in range(10, 0, -1):
>>> print(i, end=" ") # “end”参数用来避免每个值都使用新行打印
10 9 8 7 6 5 4 3 2 1
编写生成器理解:解
>>> g = ((n, n+2) for n in range(6) if n != 3)
>>> list(g) # 转化成列表来打印其中的值
[(0, 2), (1, 3), (2, 4), (4, 6), (5, 7)]
直接使用生成器理解:解
>>> sum(range(1, 101, 2))
2500
或
>>> sum(i for i in range(101) if i%2 != 0)
2500
列表理解:解
>>> ["hello" for i in range(100)]
['hello', 'hello', ..., 'hello', 'hello'] # 100个hello
高级的列表理解:解
>>> [("hello" if i%2 == 0 else "goodbye") for i in range(10)]
['hello', 'goodbye', 'hello', 'goodbye', 'hello', 'goodbye', 'hello', 'goodbye', 'hello', 'goodbye']
元组理解:解
>>> string_of_nums = "3.2, 2.4, 99.8"
>>> tuple(float(i) for i in string_of_nums.split(","))
(3.2, 2.4, 99.8)
翻译for循环:解
>>> out = [(1 if i is "o" else 0) for i in "Hello. How Are You?" if i.islower()]
>>> out
[0, 0, 0, 1, 1, 0, 0, 0, 1, 0]
内存效率:解
生成器表达式 sum(1/n for n in range(1, 101)) 比起列表理解 sum([1/n for n in range(1, 101)]) 更优。使用列表理解会不必要的在内存中创建有100个数字的列表,然后再将其输入到 sum 中。生成器表达式则在 sum 迭代时每次只生成一个数值。